The Poincaré is one model of hyperbolic space. Try it out here.
Infinity is at the edge of the Poincaré disk, aka the circle. The Poincaré is a three more dimensional bowl seen from above. Getting where you want to go requires traveling along a hyperbolic geodesic. And, projecting a future will understate your financial outcomes. Discontinuous innovation happens here.
A long time ago, I installed a copy of Hyperbolic Pool. I played it once or twice. Download it here. My copy is installed. It say go there. Alas, it did not work when I tested it from this post. My apologies. Hyperbolic space was a frustrating place to shoot some pool.
I’ve done some research. More to do.
A few things surprised me today. The Wikipedia entry for Gaussian Curvature has a diagram of a torus. The inner surfaces of the holes exhibit negative curvature. The outer surfaces of the torus exhibits positive curvature. That was new to me.

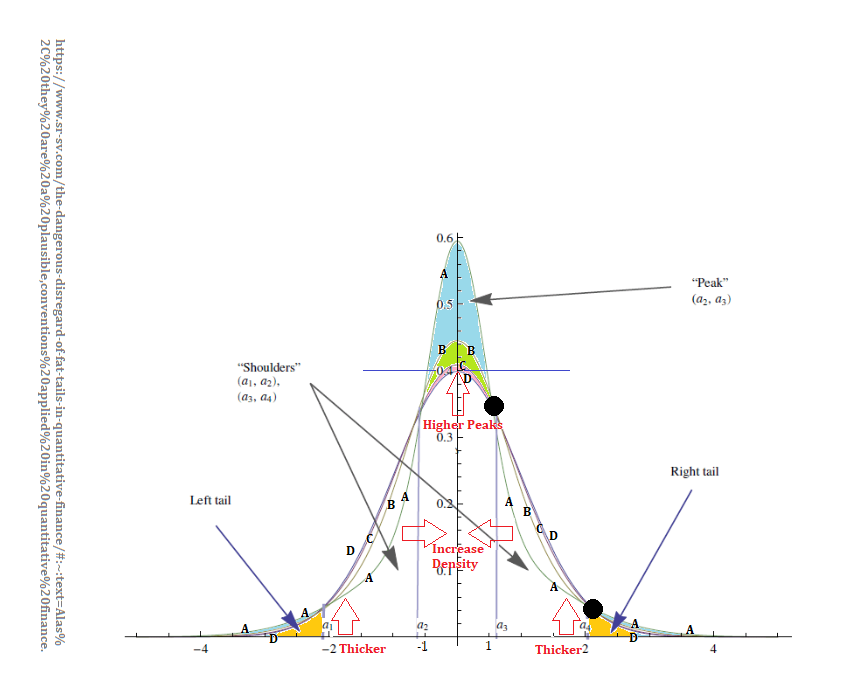
I’ve blogged on tori and cyclides in the context of long and short tails of pre-normal, normal distributions, aka skewed kurtotic normal distributions that exit before normality is achieved. These happen while the mean, median, and mode have not converged. I’ve claimed that the space where this happens is hyperbolic from the random variable’s birth after the Dirac function that happens when random variable is asserted into existence and continues until the distribution becomes normal.
Here are the site search results for
There will be some redundancy across those search results. In these search results, you will find that I used the term spherical space. I now us the term elliptical space instead.
We don’t ever see hyperbolic space. We insist that we can achieve normality in a few data points. It takes more than 211 data points to achieve normality. We believe the data is in Euclidean “ambient” space. We do linear algebra in that ambient space, not in hyperbolic space. Alas, the data is not in ambient space. The space changes. Euclidean space is fleeting: waiting at n-1, arrival at n, departing at n+1, but computationally convenient. Maybe you’ll take a vacation, so the data collection stalls, and until you get back, your distribution will be stuck in hyperbolic space waiting, waiting, waiting to achieve actual normality.
Statistics insists on the standard normal. We assert it. Then, we use the assertion to prove the assertion.
Machine learning, being built on neurons and neural nets, insists on the ambient space because Euclidean space is all their neurons and neural nets know. Euclidean space is convenient. Curvature in machine learning is all kinds of inconvenient. Getting funded is not just a convenience. It might be the wrong thing to do, but we do much wrong these days. Restate your financials, so the numbers for the future, from elliptical space paint a richer future than the hyperbolic numbers that your accounting system just gave you.
And one more picture. This from a n-dimensional normal, a collection of Hopf Fibered Linked Tori. Fibered, I get, but I stayed out of it so far. Linked happens, but I’ve yet to read all about it.

The thin torus in the center of the figure results from a standard normal in Euclidean space. Its distribution is symmetrical. Both of its tails are on the same dimensional axis of the distribution. They have the same curvature. The rest of the dimensions have a short tail and a long tail. Curvature is the reciprocal of the radius. The fatter portion of the cyclides represent the long tails. Long tails have the lowest curvatures. The thinner portion of the cyclides represent the short tails. Short tails have the highest curvatures. Every dimension has two tails in the we can only visualize in 2-D sense. These tori and cyclides are defined by their tails.
Keep in mind that the holes of the tori and cyclides are the cores of the normals. The cores are not dense with data. Statistical inference is about tails. And, regression to tails are about tails, but in the post-Euclidean, elliptical space, n+m+1 data point sense. One characteristic of the regression to tails, aka thick-tailed distributions, is that their cores are much more dense than that of the standard normal.
Hyperbolic space will only show up on your plate if you are building a market for a discontinuous innovation. Almost none of you do discontinuous innovation, but even continuous innovation involves elliptical space, rather than the ambient Euclidean space, or the space of machine learning. We pretend is that Euclidean space is our actionable reality. Even with continuous innovation, the geometry of that space matters.
Enjoy!
…